 0
0As a nascent science journalist, I don't often have a chance to write about people and places I know well. That's not true for today's blog item. A group of scientists from my home university, Villanova, and Eastern University (just down the road from 'Nova) has devised a way to combat one of the most frustrating problems facing astronomers today: information overload.
With the deluge of new ground-based instruments and space telescopes, professional astronomers have to worry just as much about analyzing the gobs of data they amass as they do about obtaining them. Some turn to amateurs for help, others to students desperate for experience (I know: they're my classmates). But some databases — like the Optical Gravitational Lensing Experiment (OGLE) survey, which among other things identifies variations in the light coming from stars — have too much information for even a sizeable group of people to sort out in a lifetime.

EBAI's program functions on a 2 GHz CPU — one of the Villanova seniors who graduated this year has it on his laptop — and can process thousands light curves in about the time it took you to read this caption.
Dennis Di Cicco
The team offers a solution with its Eclipsing Binary via Artificial Intelligence (EBAI) project, spearheaded by Andrej Prša (Villanova/University of Ljubljana, Slovenia) and Edward Guinan (Villanova). Compact enough to run on a laptop, the EBAI neural network analyzes dips in the light coming from binary systems as one component passes in front of the other. From these light curves it calculates five of the stars' physical parameters, including the ratio of their combined radii to their separation and the system's orbital inclination, which can significantly affect observations.
Now, if you're like me, your eyes glaze over when you hear "neural network." This Treky term is actually just an exciting name for a simple concept, Prša explains. A neural network has three levels: input, hidden, and output. The input layer represents the data you enter into the program — in this case, thousands of light curves taken from OGLE and the Catalog and Atlas of Eclipsing Binaries (CALEB).
The hidden layer is a sort of intermediate form or representation of the input data. Here the network consults its "knowledge" of light curves and the parameters describing the stars that create them — derived from the more than 33,000 synthesized light curves the team fed the network as "training." It then combines the light-curve data points in different ways until it finds parameters that work for the system and spits out the results. On a basic PC processor, EBAI can analyze 15,000 light curves in 10 seconds — and most of that time is spent in input and output, not computation.
The astronomers then feed these parameters into another modeling engine called PHOEBE, a community project based on a code written by Edward Devinney (Villanova) and Robert Wilson (University of Florida). With the EBAI results PHOEBE can give a good idea of the more than 50 parameters needed to fully describe eclipsing binaries, Prša says.
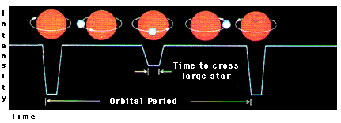
As one star passes in front of the other, the total light from the system decreases. Astronomers plot these dips as a light curve to trace the motion of the binary companions and then determine various characteristics, such as the ratio for the stars' sizes and their temperatures.
NASA-Goddard
EBAI will work for any light curve, not just those of eclipsing binaries. "We picked eclipsing binaries because they are the toughest," Prša explains. "Other types of stars rarely exhibit such a variety in parameters." Eclipsing binaries are also important because they are astronomers' only direct means to calculate both the mass and diameter of a star, he continues. Today's stellar models are largely based on what scientists have learned from eclipsing binaries.
While other researchers have successfully applied automatic data processing to survey results, EBAI is unique in how — and how fast — it solves for output, Prša says. Its results are only statistically good, though. "Values for individual stars can be good, average, or bad," he admits. "But even if it messes up for 10% of them, it still gets 90% of them right." That 90% offers a solid starting point for PHOEBE's subsequent analysis, he says.
The EBAI and PHOEBE programs are available free to anyone who wants to download, change, and contribute to them. The team's first paper will appear in the Astrophysical Journal.
About Camille M. Carlisle
Science Editor Camille M. Carlisle handles science features for Sky & Telescope. She specializes in black holes, Mars, and whatever she happens to be writing about at the time. Frolic with her through the delights of black holes in her blog, The Black Hole Files.

Comments
You must be logged in to post a comment.